Recategorización de variables y los factores 👋
ifelse(), cut() y los factores
Recategorización de variables
Es muy común tener que recategorizar variables en función de ciertos criterios o valores. Por ejemplo, la variable edad, continua, podría recategorizarse en una variable categórica según grupos o rangos de edad. Depende de los objetivos o la información que manejamos, se pueden reconfigurar variables o simplemente crear nuevas a partir de variables ya existentes.

En R hay varios modos de recategorizar variables, y algunos de estos ni siquiera son exclusivos en su objetivo de recategorizar variables. Por un lado, la función ifelse() tal vez sea el modo más rápido para crear una variable dicotómica pero el uso del ifelse no se restringe a este proposito sino que va más alla. Explicaremos todo su potencial a continuación. Por el otro, cut() sí que se puede considerar una función exclusiva para convertir variables continuas a categóricas. Personalmente, yo suelo utilizar ifelse() cuando deseo crear variables dicotómicas y cut() para politómicas.
ifelse()
Es una función base. Yo la llamo la función Mastercard, ya que su lógica podría ilustrarse con su eslogan emblema. La lógica de la función podría resumirse del siguiente modo: “si esto pasa (condición), hacemos x, y para todo lo demás, hacemos y”. Si se entiende bien su lógica, se puede intuir todo el potenial de la función, por lo que reducir el dominio del ifelse() a la discretitación de variables puede ser un poco banal.
Ilustremos un ejemplo con una materia que a todos los que aprendemos nos toca intimamente: los examenes. Detrás de la tensión de la barrera entre aprobar o suspender se esconde una lófica ifelse(). Si (if) igualas o superas un 5, apruebas, y si no (else), suspendes. Esta sencillez es la que invita a utilizar ifelse() para dicotomizar las variables. Partimos de las notas, variable continua, y acabamos en una variable dicotómica: aprobado o suspenso.
ifelse ( test = , # el test, condición
yes = , # Acción o valor a realizar cuando se cumple el test
no = ) # Acción o valor a realizar cuando NO se cumple el test
#La función tiene tres solo argumentos, pero los tres son fundamentales.
ifelse ( clase$nota >= 5, "aprobado", "suspenso") #los valores pueden ser númericos o de texto
ifelse ( clase$nota >= 5, 1, 0)
Sin embargo, también podemos recurrir a ifelse() para aplicar otras funciones dependiendo de otros valores, o hacer transformaciones básicas.
ifelse( clase$nota >10, trunc(10),nota) # Si una nota se pasa de 10, se transforma automáticamente en un 10 (nota máxima permitida), y sino, pues nada, su nota se queda igual.
ifelse( clase$asistencia == "si", clase$nota+1, clase$nota) # si alguien tiene una asistencia impecable, le sumo 1 punto a su nota, y sino, pues su nota se queda igual
cut()
Por otro lado, la función cut() se ha creado exclusivamente para la recategorización de variables. A diferencia del ifelse(), cut() es menos inteligente y en uno de sus argumentos tendremos que indicar los valores que forman los extremos de los intervalos que marcan la recategorización de la variable. Si bien su uso puede parecer simple, la función puede requerir una serie de consideraciones. Por sentido común, lo primero será fijar bien los extremos de los intervalos. Aunque esto parece fácil, tendremos que asegurarnos de incluir tanto el valor mínimo como comienzo del primer intervalo, y el valor máximo en el cierre del último intervalo. Podremos usar también las funciones min() y max(), pero sino deberemos observar con unos descriptivos o con una tabla de frecuencias cuales son esos valores. Otro aspecto a considerar será el cierre de los intervalos. Podemos cerrar los intervalos en el valor inferior, o en el superior. Para esto tendremos que considerar el argumento <code!> right . Por defecto, el intervalo se cierra a la izquierda pero si quisiesemos lo contrario, deberemos igualar el argumento right a TRUE.
# Variable inicial: math score
#── Variable type: numeric ────────────────────────────────────────────────────────────────────────────
# skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist
#1 data 0 1 66.4 15.4 13 56 66.5 77 100 ▁▂▇▇▃
cut(x = exam$math.score,breaks = c(0,56,77,100)) # Quiero formar tres intervalos. Desde el mínimo hasta el Q1, desde el Q1-Q3, y desde el Q3 hasta el max.

Como se aprecia en la imagen, la variable se crea con los intervalos, pero esta salida puede resultar, además de fea, poco informativa. Podemos dar etiquetas a cada uno de los grupos con el argumento de labels
grupo_mathscore <-
cut(x = exam$math.score,
breaks = c(0,56,77,100),
labels = c("Grupo_inferior","Grupo_medio","Grupo_superior"))
# Salida después de aplicar un table()
table(grupo_mathscore)
#Grupo_inferior Grupo_medio Grupo_superior
# 265 490 245
Factores
La clase factor en R, y en otros lenguajes matemáticos, es un modo de asegurarse que el programa interprete la variable tal y cómo la interpretamos nosotros en la realidad (como una variable categórica)
Imaginaos la variable nivel socio-económico. Puede tener 4 niveles: bajo, medio-bajo, medio-alto, alto (para quién se crea esta división). En una base datos puede aparecer codificada como 1,2,3,4. Voy a crear el ejemplo.
nivel_soc<-rep(1:4,20); # Creo un vector. Repito la secuencia 1,2,3,4, 20 veces.
nivel_soc<-sample(nivel_soc) # Aleatorizo el vector
str(nivel_soc) # Comprobamos la estructura del vector. Vector int.
#
#int [1:80] 4 3 2 3 4 2 4 1 2 3 ...
Ahora bien, cómo pensaís que interpreta esto R? Para R esto es una variable continua, que puede ser cuántas cartas legendarias de Yu-Gi-Oh tiene cada persona, cómo podría ser el número de primos que tienen.
Una idea de cómo interpreta R está variable es graficandola. Si hago plot() dibuja un scatter plot, un gráfico dispersión, que es el modo de dibujar la nube de puntos de una variable continua.
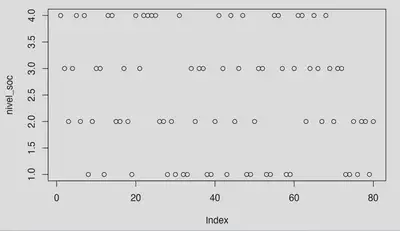
Ahora bien. Nostros sabemos qué es diferente a nivel conceptual tratar una variable cómo continúa que cómo categorica. Aquí vienen los factores.
nivel_soc_FACTOR<-factor(nivel_soc) #Convertimos sencillamente el vector en factor.
str(nivel_soc_FACTOR)
# Factor w/ 4 levels "1","2","3","4": 4 3 2 3 4 2 4 1 2 3 ...
Ahora R interpreta cada valor diferente de esta variable cómo un grupo, y una manera gráfica de ilustrar este cambio es usar plot() de nuevo.

Fijaos que ahora con la misma función hace un gráfico de barras. Justo el gráfico que querrías dibujar con una variable categórica.
Pasar variables a factor en R sirve para que R interprete la variable tal y cómo queremos.
Antes de resolver un problema es útil (casi obligatorio) pensar qué tipo de variables estás tratando. No es lo mismo una variable contínua que una categórica. Con una variable contínua puedes hacer una media, con una variable categoríca, una proporción. POR EJEMPLO.
En nuestro ejemplo, la misma variable nivel_soc , si no la pasamos a factor R está asumiendo que es una variable contínua. Así que muchas funciones lo van a interpretar de este modo. Esto es sobre todo problemático cuando la función puede esperar una variable de cualquiera de las dos clases. Por ejemplo en el ANOVA el resultado es diferente si no pasamos la variable a factor.
Adrián Muñoz García
Senior Data Scientist and Statistics Professor
My research interests are IA, Computer Science and Behavioral Economics