Sintaxis y Objetos 👋
Hello world. Empezamos a escribiR
Hello World
Como marcan los estandares en la pedagogia de la programación, los primeros pasos en cualquier lenguaje se suelen introducir con el famoso “Hello World”. ¿Por qué? Pues os vendería la moto con cualquier argumento pero sinceramente no tengo ni idea chico, ¿o es que vosotros acaso cuestionáis las tradicciones? Vamos al lío.
print ("Hello leaRners")
Sintaxis
En la sintaxis de R tenemos que diferenciar comentarios e instrucciones (el propio código). El código es aquello que R intepreterá como un “to do it”, mientras que los comentarios serán un “to read it … pero ni caso”.
Los #comentarios son útiles para describir lo que hacemos en el código, darnos pistas para cuando lo retomemos, dejar apuntes o incluso omitir partes de un trozo de código que por convenencia queremos omitir.
El código por otro lado es cuando nos comunicamos directamente con R, cuando escribimos cosas que R tiene no solo que entender, sino ejecutar. De hecho, si escribimos algo que no entiende, R nos dirá con errores aquello que está mal o que no reconoce. Como una Hermione que nos corrige si pronunciamos mal un hechizo.

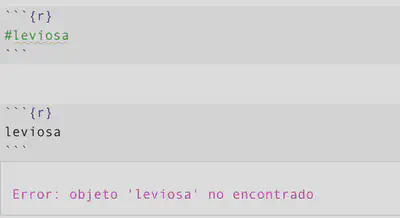
So, a la derecha de una almohadilla “R” oye pero no escucha, y una línea sin almohadilla o lo que quede a la izquierda de una almohadilla, R espera algo con sentido y lo ejecuta.
# to read it
# A la derecha de una almohadilla, todo es comentario
to do it
Sin una almhoadilla, esto es código
esto es codigo #esto no
Dicho esto, R se estructura por líneas y “oraciones” completas. Esto es lo que determina el orden de ejecución. Para ejecutar una línea debemos pulsar crtl+enter o cmd+enter en Mac
Aquello que escribamos en una línea, si está completo, R lo ejecutará junto antes de pasar a la siguiente línea. Sin embargo, si dejamos a R con la miel en la boca con alguna sintaxis, la buscara en la siguiente línea.
En el ejemplo de abajo, podemos ver tres sintaxis:
En el primer bloque la instrucción de imprimir por pantalla la frase “Hello leaRners” está escrita en una línea (36). Si ejecutamos la línea 36 aparecerá en consola la frase. Todo bien.
En el segundo bloque la instrucción está divida en tres líneas (40,41,42). Si ejecutamos la línea 40, R continuará hasta la línea 42. ¿Por qué? En la línea 40 lee que estamos introduciendo una función print(, una acción, que sin embargo no está acabda. R sabe que no está acabada porque después del parantesis (sintaxis obligatoria de una función; funcion() ) no hay nada, por lo que salta de línea para buscar como acaba la instrucción y contínua hasta encontrar el paréntesis que cierra la función.
El tercer bloque también está dividido en tres líneas (47,48 y 49). A diferencia con el segundo bloque, en la primera línea solo está escrito print. Esta instrucción sí está acabada. Aunque print() sea una función, print a secas es un objeto y para R está completa la oración, por lo que acaba en la misma línea 48. En este caso, R imprime en pantalla que print es el nombre de una función, pero no intepreta que queremos ejecutarla, interpreta que solo queremos nombrarla.
print ("Hello leaRners") # Imprimirá "Hello leaRners"
print ( # Imprimirá "Hello leaRners"
"Hello LeaRners"
)
print # No seguirá de línea
("Hello leaRners)

Funciones y Objetos en R
Siguiendo la explicación de porqué en un bloque intepreta que la estructura está completa (3º) y en el otro no (2º) es imprescindible saber como R reconoce los diferentes objetos, como sabe que en un bloque estamos escribiendo una función y que no la hemos terminado, y en el otro estamos escribiendo un objeto.
En la mayoría de lenguajes existen diferentes tipos de “unidades”: Hay verbos, preposiciones, sustantivos, etc … Y en R también existen diferentes tipos de estucturas o unidades, y es imprescindible saber como es su sintaxis general para saber qué estamos pidiendo a R como locutores y qué esta interpretando R como receptor.
Funciones
En primer lugar, existen las funciones. Ya hemos introducido de alguna manera las funciones, pero por simplificar, las funciones son las acciones que queremos realizar en R. La sintaxis de las funciones es el nombre de la función seguido de dos paréntesis
funcion() # esto es una función. El nombre de la función seguido de dos paréntesis.
#Ejemplos:
mean() # calcular media
sd() # calcular desviación estándar
print() # imprimir en pantalla
Dentro de los paréntesis podemos escribir los paramétros que necesita la función para trabajar. Imaginad que vuestro compañero se gira y os dice: “Comer”. Después del miedo instintivo que podría suscitarme una escena propia de un apocalipsis zombie o de un derrame cerebral, lo primero que haríamos sería preguntarnos qué quiere decir con comer, que es lo que quiere comer, donde quiere comer … pues lo mismo con las funciones en R. No podemos decir “Media”, tenemos que indicar el vector sobre el cual queremos calcular la media, el tipo de media que queremos calcular, etc… en fin, tenemos que añadir y sustantivos y adjetivos a la acción para hacernos entender.
Cada función está preparada para trabajar con una serie de parámetros. Un modo rápido para saber que parámetros necesitamos es situarnos dentro del paréntesis y pulsar tab . De este modo sale una ventanita emergente que sugiere los parámetros que puedes querer pasar a la función, además de una pequeña definición de lo que es cada parámetro. Otro modo es buscar la función en la ventana de help o escribiendo en consola el nombre de la función precedido de un signo de interrogacción: ?funcion
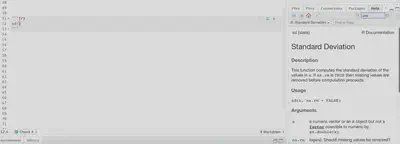
Una función puede reconocer más de un parámetro, aunque no todos los parámetros son obligatorios para funcionar. Utilicemos el ejemplo de la función sd(). En esta función se describen dos parámetros:
- x: a numeric vector or an R object but not a factor coercible to numeric by as.double(x).
- na.rm: logical. Should missing values be removed?
Es decir, podemos complementar la función con el vector o serie de números sobre los que queremos calcular la desviación estándar, además de una opción para indicar si la función debe ignorar los posibles valores perdidos del vector. Sin embargo, el parámetro obligatorio solo es el vector, ya que sin números, no hay desviación estándar. Si no dijesemos nada respecto al paráetro na.rm la función lo intepretaría vacío, y actuaría con un valor por defecto, en este caso, FALSE, o en otras palabras, NO ignoraría los valores perdidos. Ahora bien, ¿cómo pasamos los paramétros a la función? Tenemos dos opciones:
- Ordenados y sin “nombre”: Podemos respetar el orden de los parámetros. R leerá los parámetros segun el orden que se ha especificado dentro de la función. En este ejemplo podremos escribir el vector directamente, y a continuación uno de los valores que nos pide el segundo parámetro (TRUE o FALSE). Por “sin nombre” queremos decir que no hace falta escribir que el parámetro x es igual a tal vector (x=vector) sino que con escribir solo el nombre del vector, vale.En R, la dicotomía sí o no, se expresa con TRUE o FALSE:
- Sin orden pero con nombre: No hace falta respetar el orden de los parámetros pero de esto modo SÍ tendremos que especificar el nombre del parámetro. Es decir, tendremos que escribir el nombre del parámetro además del propio valor del parámetro. Si desordenamos los parámetros y no especificamos su nombre, R se confundirá y seguramente acabe en error. De alguna manera es como si la Thermomix espera que introduzcamos zanahorias, pero introducimos harina. R tiene un molde para cada función y si nosotros tenemos el descaro de no respetar el orden, que menos que tener la decencia especificar el orden que estamos siguiendo.
Los parámetros siempre se separan con una coma dentro de los paréntesis
sd(vector,TRUE) #Ordenados y sin "nombre" sd(vector) #Ordenados y sin "nombre". ___________ sd(na.rm= TRUE,x = vector) #Sin orden pero con nombre ___________ sd(TRUE,vector) # ERROR ... porque no están especificados y están desordenadosPaquetes
Después de ver las funciones, tiene sentido repasar que no todas las funciones se encuentran cargadas por defecto en R, sino que hay que cargarlas explícitamente para usarlas. Las funciones están contenidas en paquetes que podemos descargar y activar en R.
Algunos paquetes se volverán rutina para nosotros y yo me encargaré de introducirlos, pero en general, un uso común es buscar nuevos paquetes en internet que cumplan nuestras necesidades. A medida que avancemos descubriremos nuevos paquetes con formulas que nos facilitaran la vida, y aunque me encargaré de introducirlos y hacerlos explicitos con sintaxis, es necesario reconocer los mismos paquetes y como usar las funciones que guardan.
En primer lugar tendremos que instalar el paquete, para ello necesitaremos precisamente una función: install.packages() Bastará con poner el nombre del paquete como argumento (entre comillas) y se instalará automáticamente después de ejecutar el comando.
Una vez que instalemos el paquete no hará falta volver a instalarlo cada vez que queramos usarlo, se guardará como un archivo más en nuestro ordenador. Podemos ver todos los paquetes instalados en la ventana de R Studio de “Packages”.
Después de su instalación, tendremos que activar el paquete para usar las funciones que hay dentro. Para esto en realidad hay dos maneras:
Activarlo de manera general: Podemos activar el paquete y todas sus funciones a través de la función library(nombre_paquete). Si ejecutamos esta línea ya podremos usar de manera directa todas las funciones que contiene. Por ejemplo, el paquete psych incluye la función describe() muy útil para calcular descriptivos de una manera muy directa.
Llamar a la función con el paquete: En vez de activar el paquete, podemos usar cualquier función que pueda contener si nombramos al mismo paquete antes de la función de la siguiente manera: paquete::funcion(). De hecho, yo me acostumbraré a escribir las funciones de esta manera para explicitar el nombre del paquete y estimular la memoria. Con el ejemplo de psych, podriamos utilizar la función describe() del siguiente modo: psych::describe().
Las funciones suelen tener nombres intuitivos. Si queremos instalar paquetes, la función no se llamará alohomora(), tiene sentido que se llame algo como install.packages(). Usad la lógica
install.packages("psych") # Descargar el paquete. Solo hará falta una vez, la primera library(pysch) # Activar el paquete de manera global. describe() #Función dentro del paquete psych psych::describe() # Podemos usar la función también sin activar el paquete siempre que nombremos el paquete antes seguido de ::
Objetos. Clase.
Por último nos quedan los objetos. Los objetos serán aquellos que recibirán las acciones. Tal vez, lo primero que hay que señalar es que hay dos “naturalezas” o clases principales. Los objetos pueden ser de clase númeric (números) o character (letras). Los números se escribirán directamente, mientras que los elementos tipo character estarán entre comillas. Existe otra clase de objeto que son los factores, pero los repasaré más adelante.
53114 #numeric "adrian" #characterLos objetos podrán ser guardados y modificados. Esta es una de las razones por las que R es útil. Imaginaos que en Word no pudieseis guardar documentos para recuperarlos en el futuro y/o modificarlos. Para guardar los objetos les daremos un nombre y se lo asignaremos con un “=” o un “<-”. Es común utilizar el operador “<-” en R para no confundirse en otros procesos más avanzados. Una vez que guardamos los objetos se encontrán en nuestro “Environment” y podremos llamarlos a través de su nombre cada vez que queramos. Siguiendo el ejemplo de abajo, si guardo bajo el nombre “numero” el número 53114, cada vez que escriba “numero”, saldrá el 53114. Pero atención, lo que es una ventaja puede jugarnos malas pasadas. En R, no existe el todopoderoso ctrl+z que nos permite deshacer cambios, y si sobrescribimos un objeto, se modificará sin poder volver atrás. Entiendase que no es una perdición, podemos iniciar de nuevo el proceso, para eso están los scripts, simplemmente no podemos confiar en un “deshacer”. Si al objeto que he llamado numero lo modifico y escribo numero <- 544, a partir de ahora, numero será 544 y no 53114. Esto no quiere decir que si utilizamos el objeto, por ejemplo en una suma, ya se guarde automáticamente. Los objetos solo se sobreescriben cuando los asignamos o sobrescribimos, con el símbolo <-.
numero <- 53114 letra <- "adrian" numero + 5 # el resultado sería 53119 numero - 1 # el resultado sería 53113 numero <- numero -1 # si volvemos a asignar el objeto numero, a partir de ahora si volvemos a escribir numero será 53113Estructuras de objetos
Existen varias estructuras de objetos. Uno de los motivos por los que existen varias estructuras u organizaciones de datos es la diversidad que existe a la hora de trabajar con los mismos. A pesar de que existen muchos tipos de estructuras, creo que a este punto merece la pena explicar las dos principales: vectores y data frames.
Vectores
Los vectores son “líneas” de datos, ya seán númericos o de tipo character. Si nos situamos en un entorno conocido como el Excel, un vector sería una columna o una fila. A medida que avancemos con los conceptos de estadística también podremos identificar los vectores con variables, sobre todo cuando son columnas en data frames
Los vectores se pueden crear con una función: c() . La c deriva de concatenar, que en otro español más de calle significa unir. Es decir, para crear vectores unimos varios elementos. Los vectores también tienen clase y NO podemos mezclar clases en un mismo vector.
nombres <- c("Adri", "Jesús", "Belén") #vector con clase character. Esta variable la llamo nombres. notas <- c(5, 8.5, 7) #vector con clase numeric. Esta variable la llamo notas.Dataframes
Siguiendo la analogía con Excel, si los vectores son las filas o columnas, los data frames (df a partir de ahora) serán la base de datos. Un df es un objeto bidimensional. Si los vectores son una línea plana (unidimensionales), los df estarán compuestos de filas y columnas. Los data frames tienen una sintáxis concreta: df[] y podremos acceder a sus elementos especificando su posición o índice dentro del dataframe.
Como si fuese un hunde a la flota, podemos especificar las coordenadas a las que queremos acceder. Para ello, dentro de la sintaxis df[], podremos imaginar siempre una coma en medio que separa a las dos dimensiones: filas y columnas. De tal manera, si quiero acceder a la primera fila puedo escribir df[1,] dejando el lado de las columnas vacío. Si quisiese solo acceder a la primera columna sería al contario df[,1]. De esta manera, accediendo a filas o columnas, el resultado que nos devolvería la consola serían vectores, sin embargo, podríamos acceder solo a un elemento concreto, por ejemplo el cruce de la fila 3 con la columna 2 df[3,2].
Para ejemplificarlo, he unido en un df los vectores que hemos creado arriba. El df tendrá una dimensión de 3 x 2: tres filas x dos columnas. Si quiesese acceder a la nota que ha sacado el tercer alumno podría obtenerla directamente llamando al df y especificando los índices a los que quiero acceder: evaluacion[3,2].
evaluacion <- as.data.frame( # creo un df llamado evaluación después de unir dos vectores como columnas con la funcion cbind() cbind(nombres,notas) # cbind() viene de column bind o unir columnas. ) ###### evaluacion[1,] #accedo a la primera fila evaluacion[,1] #accedo a la primera columna evaluacion[3,2] #accedo al elemento que cruza la tercera fila y la segunda columna, es decir, la nota del tercer nombre del df. evaluacion[4,1] # nos daría error, porque las posiciones están fueras de las dimensiones de nuestro df. Nuestro df solo tiene 3 filas, por lo que no existe la fila 4.Igual que podemos cambiar los objetos que hemos guardado, podemos añadir o modificar los elementos que se encuentran dentro de un vector o un df. Para ello, simplemente tendremos que acceder a los elemenos en cuestión y sobrescribirlos como hemos explicado antes, con el comnando <-.
Las filas se corresponderán con observaciones, y las columnas con variablesevaluacion[3,2] <- 9 # cambio la nota del tercer alumno a un 9 evaluacion[4,] <- c("Ron Weasley",4) # Puedo añadir una nueva observación o fila. En este caso, tengo que añadir una observación completa, con lo que tengo que añadir un vector con elmento para cada variable que contenga el df. En este caso será un vector con un nombre y una nota.Los df permiten filtrar los elementos en base a condiciones y conjuntos de datos. Por ejemplo, podría acceder a las primeras diez filas de un df, o solo a aquellas observaciones que cumplan que sean mayores que cinco en la columna nota. Todo esto lo explicaré con más detalle en la sección “navegando por los df.”
Adrián Muñoz García
Senior Data Scientist and Statistics Professor
My research interests are IA, Computer Science and Behavioral Economics